Nowa era, nowe wyzwania
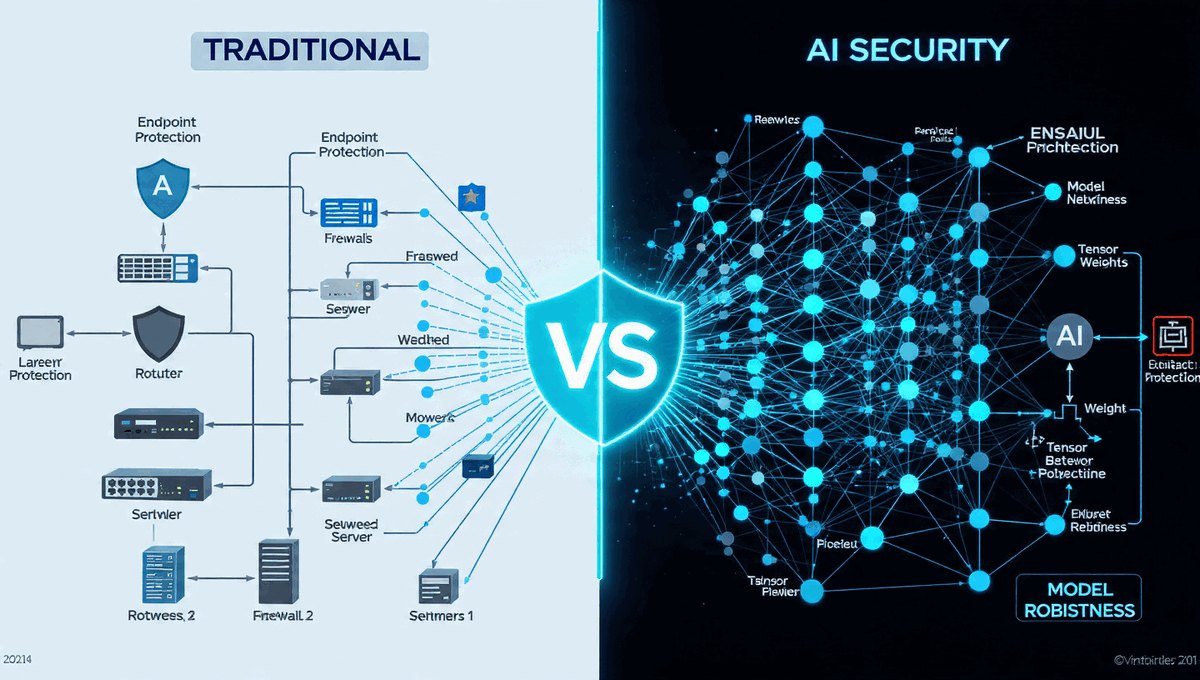
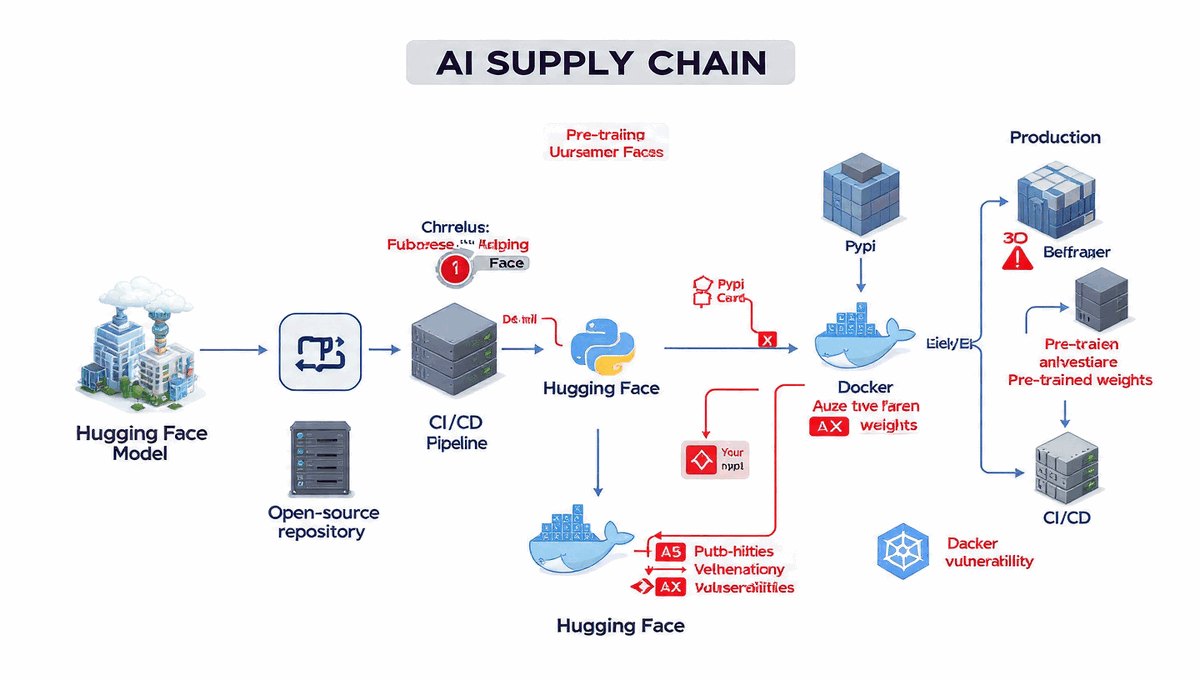
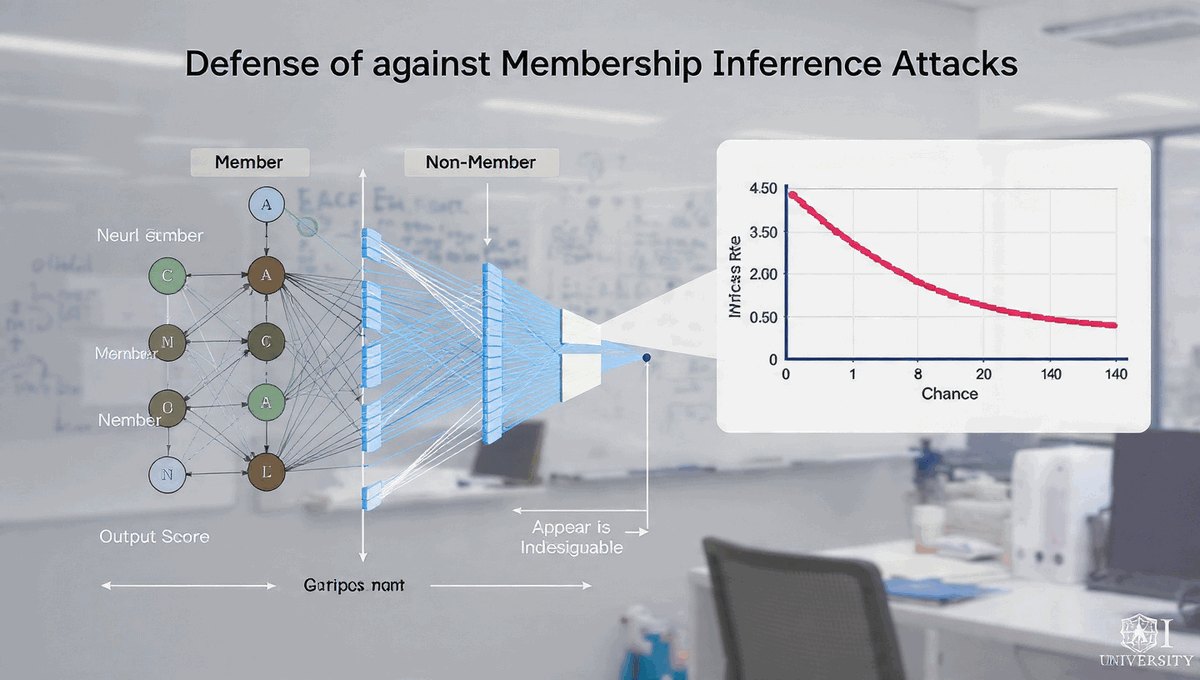
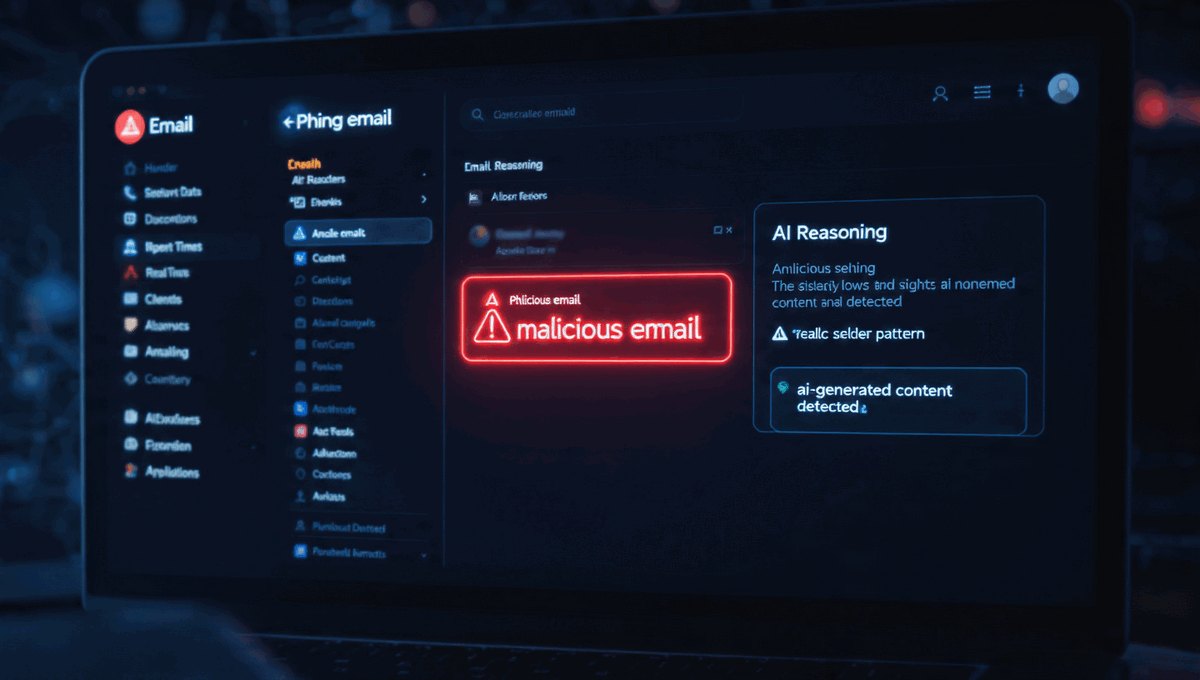
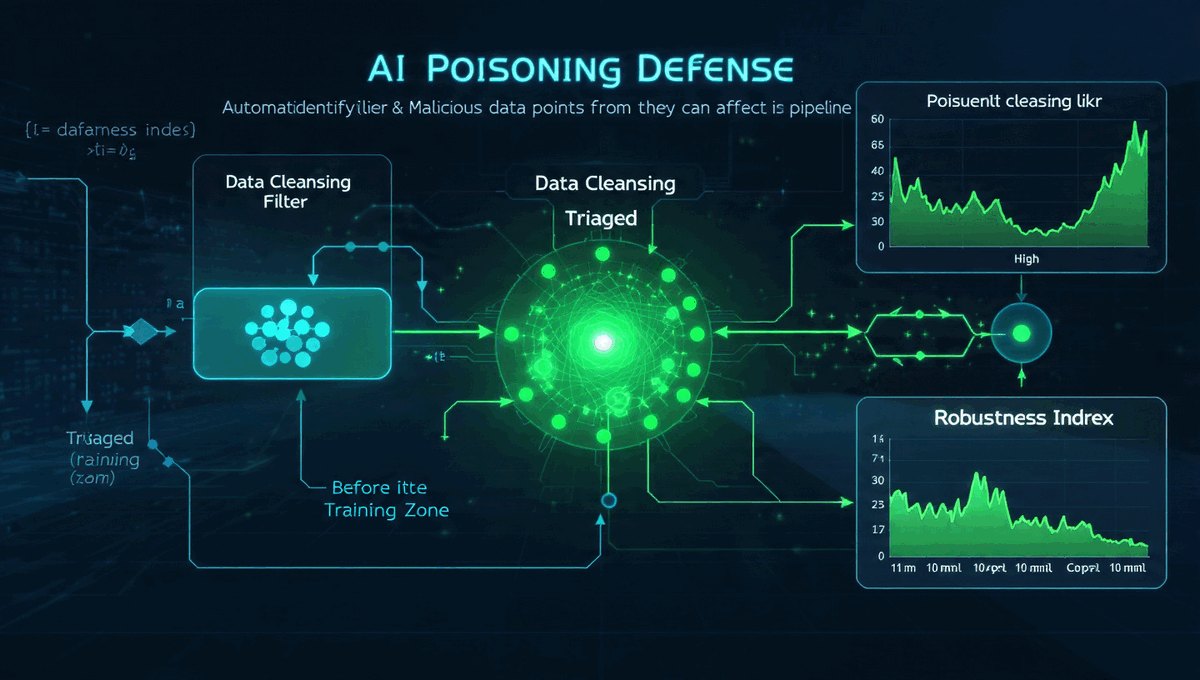
Witamy na kursie poświęconym bezpieczeństwu w świecie zdominowanym przez algorytmy AI. Technologia ta zmienia wszystko – od sposobu, w jaki pracujemy, po metody, jakimi atakują nas cyberprzestępcy.
Zrozumienie tych mechanizmów to dziś podstawowa umiejętność każdego użytkownika komputera, a dla przyszłych informatyków – fundament wiedzy zawodowej.
- Cel: Poznanie realnych zagrożeń.
- Zakres: Od wycieków danych po deepfakes.
- Podejście: Techniczne, ale przystępne dla każdego.